


Optimizing and Tracking EBS Volumes
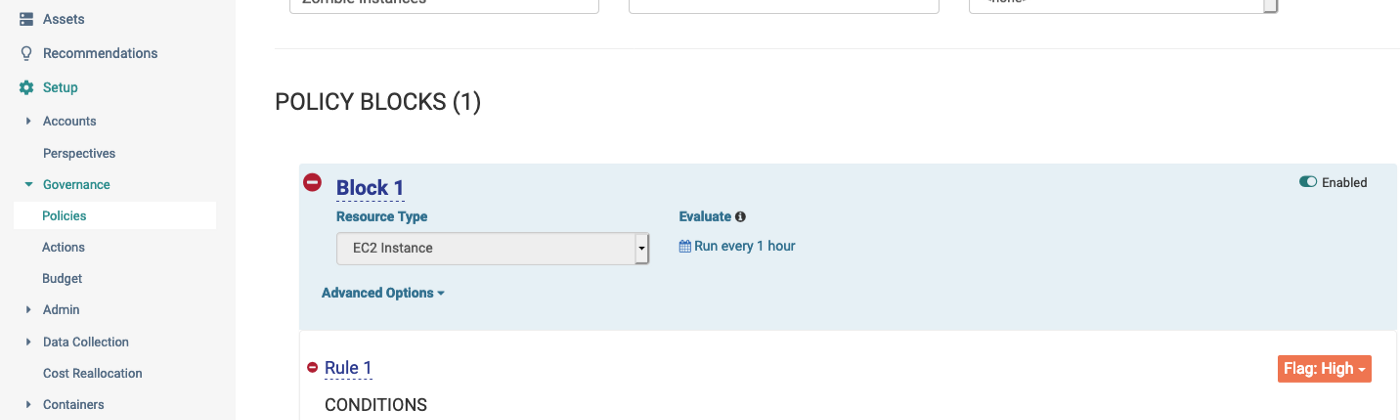
A fair number of people asked a question around what happens to the EBS volumes on my previous entry on Zombie EC2 instances? Could we insert a step in the middle or towards the end to tag and delete the EBS volume once we have a snapshot? AWS EBS volumes can be a little tricky to track and cost optimization itself is not just about reclaiming them from being used. There are couple of issues we run into.
Firstly, in the app we deployed as an example, we didn’t actually tag the volumes. If we checked the AWS console, we have 40 odd EBS volumes just in us-east-1, 30 odd in us-west-1, you get the idea. We’re likely north of 100 EBS volumes and none of them are tagged to map them back to instances. The same goes for snapshots. If these are not tagged appropriately, how do you know what it maps to? For this reason alone, please tag your AWS resources! I cannot stress this enough and if you are interested, you can find extensive resources on this topic towards the end of this blog.
Secondly, I often find people confusing EBS volumes with EC2 local storage. EC2 instances have local disk attached, which is non persistent. The local storage starts, dies with the EC2 instance itself. The instance storage is ideal for temporary storage. It does not persist through instance stops, terminations or hardware failures. On the other hand, EBS volumes persist the data through instance stops, terminations. These can be backed up with EBS snapshots. We can then attach/detach EBS volumes between EC2 instances within the same AZ if we so desire.
Thirdly, what kind of EBS volume do we need? You can go through a large matrix of choices here between IOPS, throughput and based on that you have the option to pick the appropriate volume type. This is covered extensively by AWS in their documentation —
In this blog, we’ll explore:
- Tagging EBS volumes after they’ve been deployed
- Identifying orphaned volumes
- Find severely underutilized EBS volumes
- Rightsizing and Migrating EBS Volumes
Tagging EBS Volumes after they’ve been deployed
Given that we’ve already deployed several instances of the application already, we can already see in the AWS console that none of our volumes actually map back to instances they are attached to. Ugh!
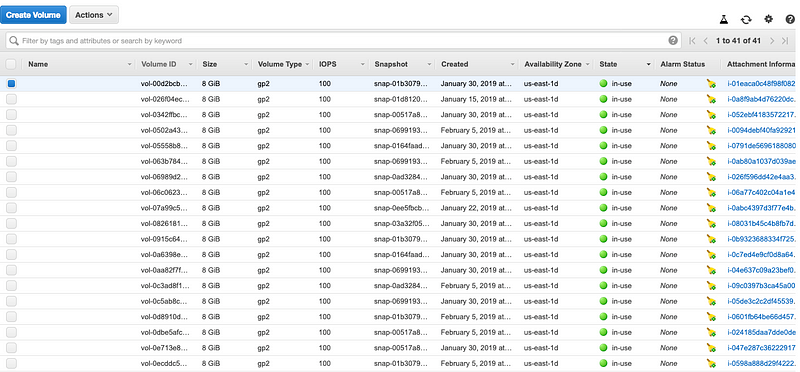
So how do we solve this? Either we go through this manually by hand or we script this out? Well, I have a third option- always search before you start writing your own lambda function, you’ll likely find something on Stackoverflow :)
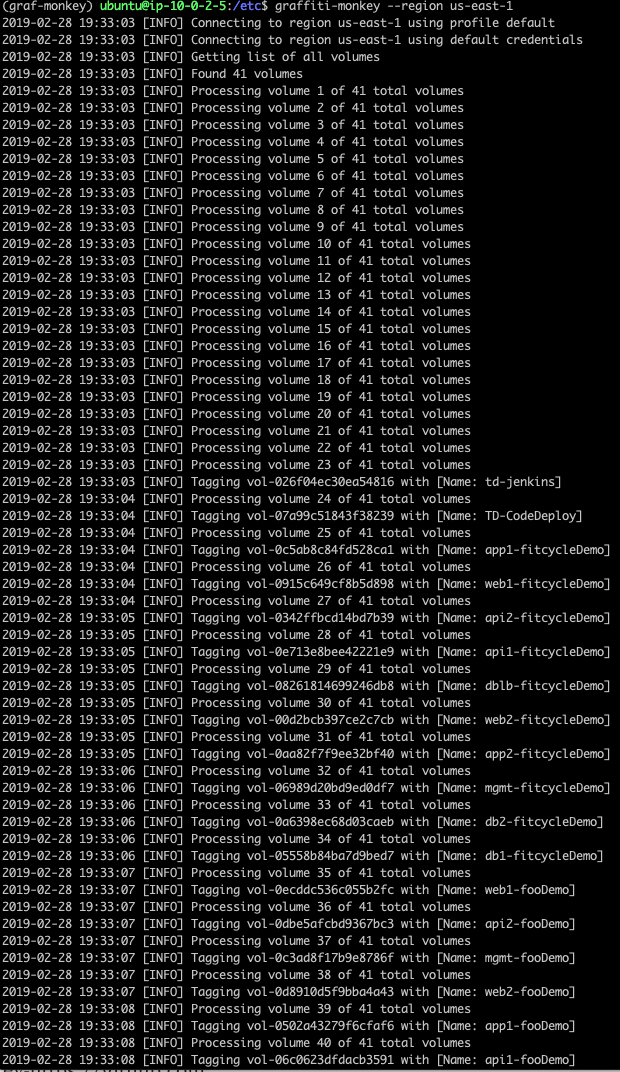
The easiest one I found thus far is Graffiti Monkey.
The script is pretty slick, where it used the “NAME” tag and added it from EC2 instance to the EBS “NAME” tag, making them equivalent. I chose to run this locally just for simplicity, but you can run this as a lambda function. The installation steps are pretty well documented in the README above. Once you’ve set it up, run the script against a specified region and it sets the appropriate tags on the EBS volumes and snapshots as you can see below. Pretty neat!!
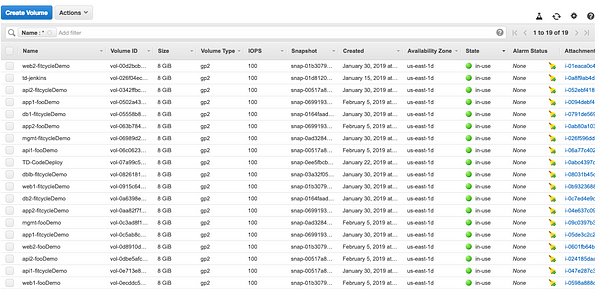
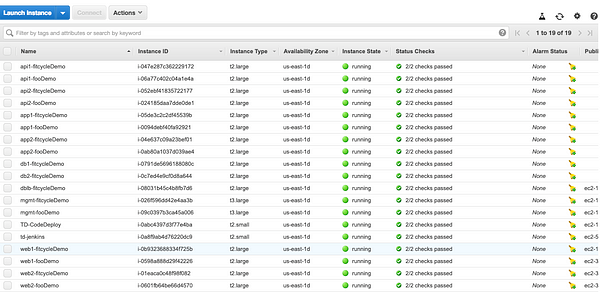
On a related note - CloudHealth Perspectives have dependency mapping. So if you tagged an EC2 instance, but not the attached EBS volume (or any other dependant asset for that matter), we’ll still map it to the right Perspective group! As you can imagine, it is pretty powerful to have this context mapping done automatically in the backend.
Identifying orphaned volumes
Like I mentioned above, EBS volumes provide the “persistent” storage option even if the EC2 instance gets deleted/destroyed. In most cases, we find that developers and operators create a snapshot of the EC2 instance and delete the instance, but in the process don’t necessarily delete the EBS volume. These volumes that are no longer attached to instances go into “available” state if we check on the AWS Console. We often find that these are all over dev/test or production gets overrun by these EBS volumes.
There are few ways to achieve this. In this example, we’re going to be using CloudHealth by VMware. First, we can find a list of underutilized instances using the Health Check feature. Secondly, if we need to get a full list from the AWS assets and their associated cost.
We do want to be careful when we approach these situations before we delete EBS volumes. Let’s look at the steps to create a governance policy that will ensure we are targeting “older” volumes. Especially in non-production environments, its a safe bet that if its not been attached over a month or so, it’s a good candidate to be deleted. So first step let’s identify these resources. The easiest way to identify these resources is by browsing to *Assets > AWS > Volumes *and then use the smart filter to identify the volumes in “available” state as shown below.

Once you get the results, this results might not immediately indicate the attach/discovery date. Click on the Edit Columns option, to add/delete the ones that we need. Here we’re interested in the attach/discovery date.
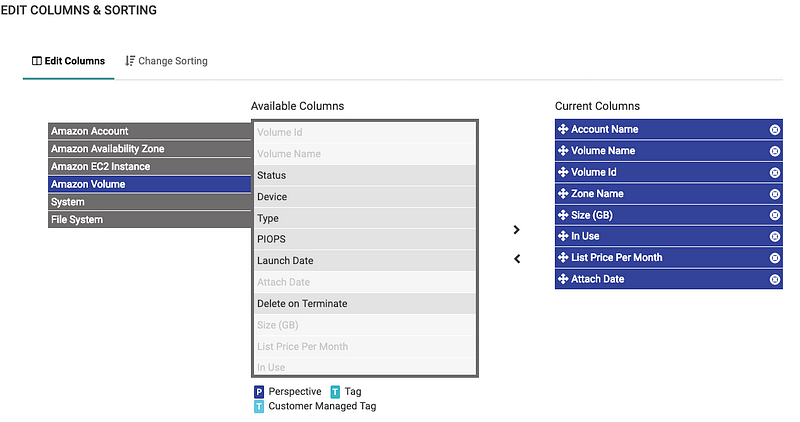
This gives us a full list of all EBS volumes in all regions, all accounts that in unattached.
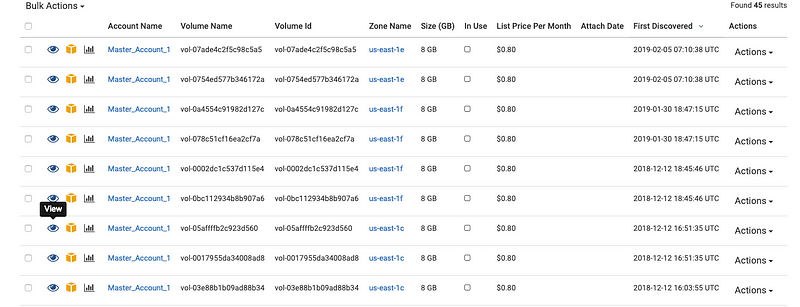
Given, these have been detached for sometime, its safe to use one of the out of the box actions. We still can snapshot them just in case and then run the delete EBS volumes action. We do have the option to introduce the authorizer step in the mix to have an approval step so that they can execute this function.
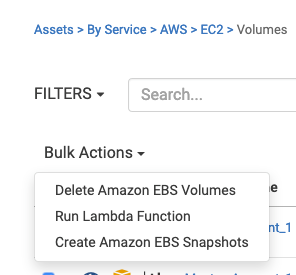
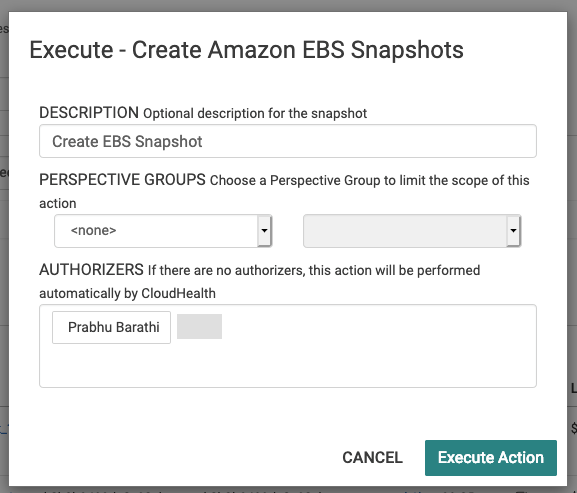
If you do need to restore from the snapshot that we’ve created, the AWS EBS Snapshots documentation outlines the steps nicely. https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/EBSSnapshots.html
Finding severely underutilized EBS Volumes
CloudHealth’s EBS Volume Rightsizing report is a great place to start finding severely underutilized EBS Volumes. There are a few options to get this. First, is under the Pulse > Health Check. You can find a lot more detail on the Health Check feature itself in other CloudHealth blogs, but we’re more interested in the EBS Volumes itself.

Before we proceed, a question that you’re likely asking yourself is how did CloudHealth know and what metrics did it use to calculate this? Well, even if you weren’t asking that question, you’re now likely wondering. CloudHealth collects metrics on both a granular level and macro level data on Read/Write Bytes, Read/Write IOPS, Read/Write Time, and Throughput. The sources range from AWS Cloudwatch , Chef or the CloudHealth agent. Once we have that information, we use the default CloudHealth guidelines to help determine these severely underutilized EBS volumes:
The default policy enabled for rightsizing volumes is as follows:
Usage
- Severely Underutilized: Average Used % < 35%
- Moderately Underutilized: Average Used % >= 35% and Average Used < 50%
Read Throughput
- Severely Underutilized: Average Read Ops % < 20%
- Moderately Underutilized: Average Read Ops % >= 20% and Average Read Ops < 50%
Write Throughput
- Severely Underutilized: Average Write Ops % < 20%
- Moderately Underutilized: Average Write Ops % >= 20% and Average Write Ops < 50%

Rightsizing and Migrating EBS Volumes
Rightsizing of the EBS Volumes in itself can take up its own blog and has varying methodologies. Here we’ll look at a simple approach to consider the option of migrating to sc1 and st1 volume types from gp2’s. You can find the details on the EBS Volume Types from the AWS blog here:
To keep it simple, the main reason we chose these volume types was because these volume types perform well for applications that are not I/O intensive, do not require millisecond latency. In order to run an evaluation to find the appropriate workloads to transition, let’s look at the metric reports and look at the average I/O levels. NOTE: the sc1 volume type cannot be used for boot volumes. If you’re looking to transition boot volumes, then use gp2, io1 or standard volumes.

Once we generate the report, sort the volumes by max read/writes (MB/H) to find the volumes and instances that have the high throughput volumes. From the AWS documentation above, sc1 volumes can sustain 250 mb/s or 90,000 MB/H which is far more than what the instances require as seen below.
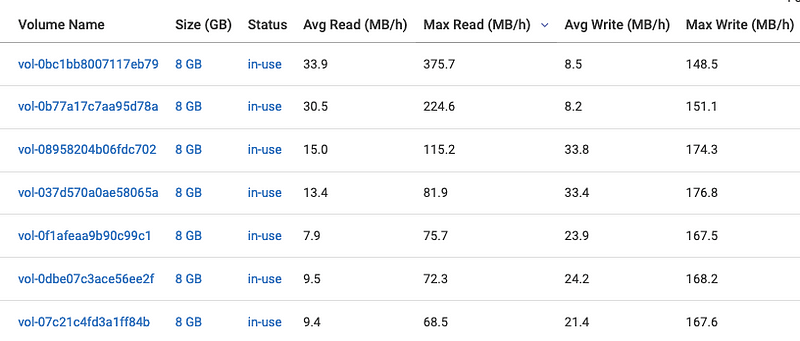
So once, we’ve narrowed the list down, let’s bring in our lambda function that will help migrated these from gp2 to sc1.
import sys
import botocore
import boto3
from botocore.exceptions import ClientError
from arnparse import arnparse
def lambda_handler(event, context):
ec2 = boto3.resource('ec2', region_name='us-east-1')
client= boto3.client('ec2')
lambdaFunc = boto3.client('lambda')
print('Trying to get Environment variable')
if event['resource_arns']:
for item in event['resource_arns']:
citem=arnparse(item)
if citem.resource_type=='instance':
ec2instance=str(citem.resource)
try:
volumes=client.describe_instance_attribute(InstanceId=ec2instance, Attribute='blockDeviceMapping')
VolumeId=volumes['BlockDeviceMappings'][1]['Ebs']['VolumeId']
print('***Volume ID is *** ', VolumeId)
response = client.modify_volume(VolumeId=VolumeId,VolumeType='sc1',Size=500)
print('***Success :: conversion ***', ec2instance)
except ClientError as e:
print(e)
else:
print("No resources found")
return { 'message' : "Script execution completed. See Cloudwatch logs for complete output" }
The sample code above iterates through the instances we provide and looks for the non-boot disk and converts them to sc1 instance type. The input to the Lambda function is as follows:
{
"resource_arns": [
"arn:aws:ec2:us-east-1:123456789:instance:i-78278188010"
],
"function_name": "ebs-conversion",
"region": "us-east-1"
}
Summary
Optimizing EBS volumes is a non-trivial task but leveraging platforms like CloudHealth and some automation through AWS Lambda functions can result in significant savings. Have you tried any other ways that have helped you reduce cost? Reach out to us to chat more.
~Prabhu Barathi


